Blog Posts
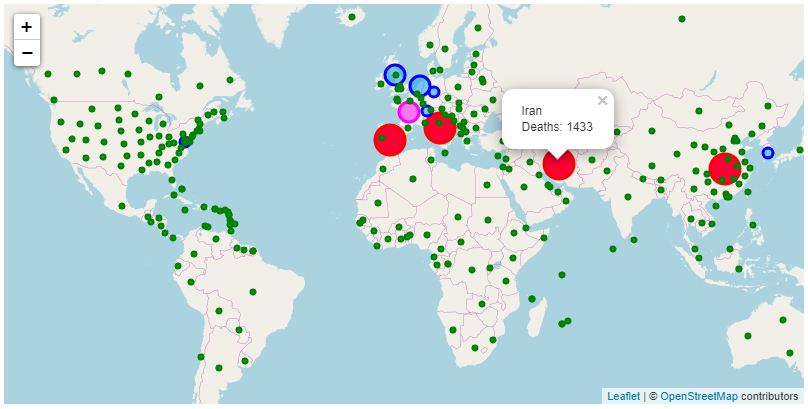
Mapping Coronavirus
With the recent worldwide crisis regarding the Coronavirus I thought it appropriate to develop a little mapping app to help visualise the virus spread. Every time there is some sort of crisis I always think it would be handy to have something to map such incidents. So this time I...

Data Quality in Local Government
Data quality is the evaluation of the information held by an organisation and to what degree it serves its collection purpose. In short, how well the information does its job. In local government, the job expected of the data it holds has changed over the last decade. Technology has increased...

Using Cloudflare for HTTPS
I've been using Cloudflare for a number of years to manage DNS settings for the various websites I look after. It's handy having all your DNS stuff in the one location and user interface rather than having to hop around to different hosts/domain providers and always having to look up...

Wordpress Redirect Loop After Changing URL
Ok - you've made a change to your URL settings in your Wordpress dashboard and you go to test your new URL and find that your site is now unavailable with the browser giving you the message that there are "too many redirects". Of course, now that the site is...

How to install Nodejs on Windows
In a nutshell, Node.js installs on Windows in the same way that you install any other Windows program. Double click on the installation executable/program/msi - and that's it.
- Go to the Node.js website and download the Node.js executable for your version of Windows. You will often see multiple versions available...

I hate video tutorials
Please stop making video tutorials about coding subjects. Stop it or you'll go blind - no seriously. I cannot stand video tutorials. When I do a search for information on learning a new technique I dread that awful feeling when arriving at the page only to see that big rectangle...

Some kind of disk I/O error occurred - SQLite
I got the extremely helpful "Some kind of disk I/O error occurred" message using the System.Data.SQLite .net assembly today. This was a big SQLite show stopper. So I thought it was about time I figured out what was causing this. The error was occurring when I tried to post an...

Calling ASP.net pagemethods from ExtJS
I use asp.net PageMethods in conjunction with ExtJS almost on a daily basis. PageMethods are simply server side methods that are callable from client side script. However, Microsoft assumes that you will be using PageMethods in conjunction with its Ajax framework, in particular the ScriptManager control which creates a JavaScript...