Data Quality in Local Government

Data quality is the evaluation of the information held by an organisation and to what degree it serves its collection purpose. In short, how well the information does its job. In local government, the job expected of the data it holds has changed over the last decade. Technology has increased customer service expectations and councils' drive to meet those expectations has driven the demand for more "joined-up" thinking across departments and better data quality.
In days gone by council departments often operated as semi-autonomous organisations and maintained "silos" of information. If a customer wanted information on their council tax they had to phone the council tax department. If they wanted information on their planning application they had to phone the planning department.
With the rise of the internet, customers increasingly expect to access their information online. And navigating department ping-pong is no longer acceptable.
Simultaneously with these technological developments has been an increasing expectation within the business of what can be done with the data held by the authority as well as financial pressures to increase efficiencies and reduce duplication of effort. Learning from private industry council leaders expect to be able to mine the authority's data to better understand their customers and develop policies to meet their needs.
At the same time council budgets have been declining rapidly under central government budgetary pressure. The need to do more with less has prompted the search for savings in the internal processes of the organisation. Duplication of effort in the various data silos across authorities' departments has been a common target for efficiency savings. In the past, for example, it has not been uncommon for many departments to maintain their own separate (and often incompatible) address databases. It makes obvious sense to manage address data within a single location and give departments the ability to look-up and validate address data from this single point of entry.
Meeting Data Quality Goals - Data Quality Management
Data quality management is defined as the management of people, processes, technology and data within an organisation. The goal is a to continually access and measure data quality and ensure it is meeting the needs of the organisation.
This is a continuous process and not a one-off event. Data changes and business needs themselves change. As a result, Data Quality Management can be thought of as a cycle.
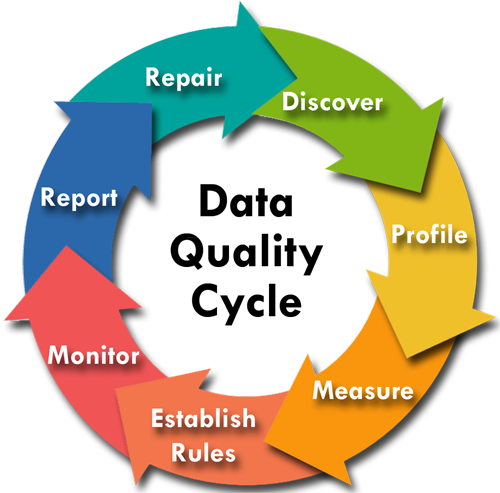
Discovery
Data discovery is the process of finding what is out there. Identifying what file systems or database servers contain the data. Then assessing how the data is structured; what the database schema is: the names and definitions of tables, fields, and relationships.
Profiling
This is an interrogation of the actual data and a comparison of this with the metadata gathered in the discovery phase. Ideally, a tool specifically designed for data profiling should be used to avoid preconceived ideas about the nature of the data and data blind spots. Although it may be necessary to develop additional queries and reports for specific aspects of the data not covered by the profiling tool.
The outcome of this process is that data statistics will be generated and stored alongside the discovery metadata.
Measure
Measuring data quality is the key step in the data quality cycle. This is where you assess the actual quality of the data. There are 8 aspects of data common to all datasets that need to be assessed:
- Completeness: How much of the required data is present? Are required fields populated?
- Uniqueness: What is the extent of data duplication? Are values or records stored more than once?
- Validity: Do all records store the allowable values for what they are supposed to be representing?
- Accuracy: Relationship of the data to the real world or another trusted source.
- Integrity: Does the data abide by the defined data relationship rules - primary and foreign key relationships.
- Timeliness: The availability and accessibility of the data. Can you get to the data quickly and easily?
- Consistency: Do data values extracted from differing datasets contradict each other?
- Representation: Are the data values represented in a way that is most useful. Is this the best way to store these values?
Rules
Data quality rules are determined by business needs and are typically the responsibility of the various data custodians. In particular, values should be identified that are vital to the business and strict rules applied to those values to ensure compliance on an ongoing basis.
Monitoring
Data quality monitoring is again determined by business needs. This is the stage where the data quality rules are either applied or assessed periodically at a frequency determined by the business.
Data exception thresholds are typically defined and once these thresholds are breached, notifications to the appropriate person should be generated.
Reporting
Data quality reporting is the companion of the monitoring process. The monitoring process captures and stores quality exceptions defined by the quality rules and reporting presents this data in a manner that is easily understood by business users. Typically this may be in the form of dashboards, excel reports, graphs or web pages.
Repair
The monitoring and reporting functions draw attention to data exceptions and problems. The data repair phase is where such issues are fixed.
Investigation of the root cause of the exceptions is performed and a solution developed to address the issue. In most cases, a data repair plan of some sort will need to be developed to implement the solution and approval sort from the data owner and IT.
To Finish Up
I realise I've only scratched the surface with data quality management as it pertains to local government. I'm hoping to be able to go into more depth with the specific steps of meeting data quality goals and the particular obstacles found within the local government environment.